Un tableau de données (dataframe) permet de regrouper des vecteurs de même taille, mais
pas nécessairement de même type (contrairement aux matrices) :
| |
math |
anglais |
russe |
sexe |
| 1 |
10 |
5 |
15 |
homme |
| 2 |
12 |
13 |
NA |
femme |
| 3 |
5 |
7 |
5 |
femme |
| 4 |
9 |
12 |
NA |
homme |
| 5 |
13 |
5 |
10 |
homme |
Un tableau de donnees
Il existe de nombreux moyens pour créer ce tableau :
en lisant le fichier texte notes.txt
(à sauvegarder auparavant sur votre disque dur)
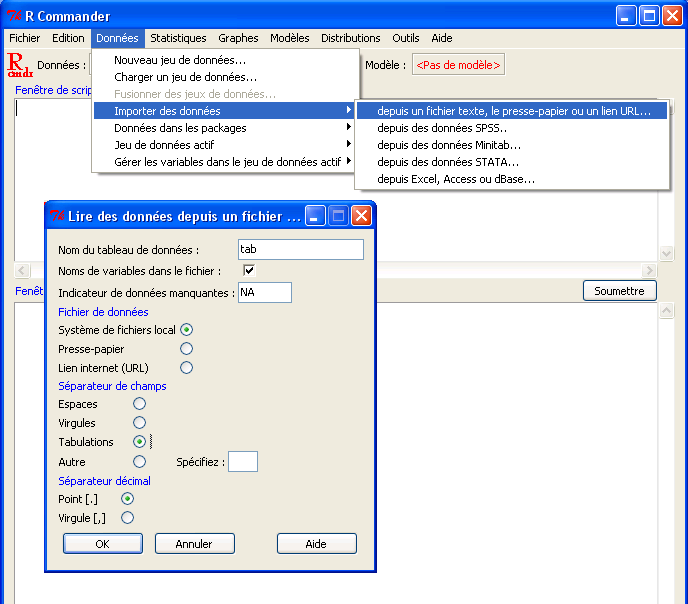
avec RCommander
(voir écran)
ou avec la fonction read.table...
# creation avec read.table
setwd("C:/Documents and Settings/raffinat") # dossier à adapter
tab = read.table("notes.txt",header=T, sep="\t", dec=".")
print(tab)
# creation avec data.frame
sexe = c("homme","femme","femme","homme","homme")
math = c(10,12,5,9,13)
anglais = c(5,13,7,12,5)
russe = c(15,NA,5,NA,10)
tab = data.frame(math,anglais,russe,sexe)
print(tab)
On peut supprimer des colonnes (russe) ou en ajouter (moyenne, avis) :
tab$russe = NULL # pour supprimer la colonne russe
tab$moyenne = (tab$math + tab$anglais)/2
tab$avis = ifelse(tab$moyenne<10,"recale","admis")
print(tab)
Pour désigner une variable d'un tableau de données, on peut utiliser
une notation de liste ($) ou une notation matricielle ([ , ]).
# notations pour désigner une colonne (ici anglais)
tab$anglais
tab[,2] # on omet l'indice de ligne
tab[,"anglais"] # indice de colonne remplacé par son nom
# notations pour désigner plusieurs colonnes
tab[,c(1,2)] # on omet l'indice de ligne
tab[,c("math","anglais")]
Comme pour les matrices, il est possible d'indicer les lignes par
des vecteurs booléens.
Cela permet d'extraire des sous-ensembles du tableau de données
initial, par exemple les données relatives aux femmes.
# selection des donnees relatives aux femmes
femmes = tab[tab$sexe=="femme",]
# on omet l'indice de colonne
# equivaut ici à tab[c(F,T,T,F,F),]
print(femmes)
# moyenne d'anglais des femmes
mean(femmes$anglais,na.rm=T)
mean(tab[tab$sexe=="femme","anglais"],na.rm=T)

{kind=link}